In the era of rapid technological advancements, Machine Learning (ML) has emerged as a transformative force, driving innovation across industries. To effectively manage and deploy ML models, MLOps has become a critical component of the data science workflow. Kubeflow and MLflow are two popular open-source platforms that have gained significant traction in the MLOps domain.
Understanding MLOps
Before we dive into the comparison, let’s briefly recap the concept of MLOps. MLOps is a set of practices that aim to deploy and maintain ML models in production reliably and efficiently. It involves a collaborative approach between data scientists and operations teams to streamline the entire ML lifecycle, from data ingestion and model training to deployment and monitoring.
Kubeflow: A Comprehensive ML Platform on Kubernetes
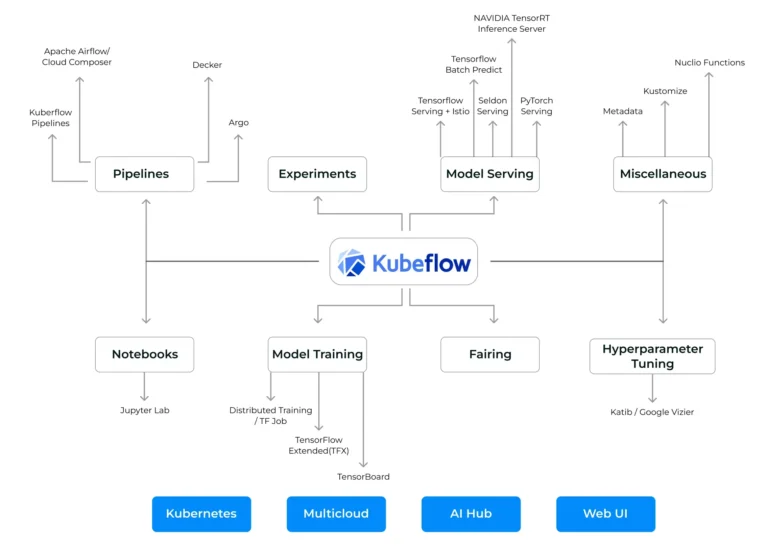
Kubeflow is a comprehensive machine learning (ML) platform designed to harness the scalability and flexibility of Kubernetes for managing the entire ML lifecycle. It streamlines the orchestration of complex ML workflows through a suite of robust tools tailored to every stage of the ML process.
Kubeflow Pipelines simplifies the creation and automation of ML workflows, enabling seamless pipeline management. For interactive model development and data exploration, Kubeflow Notebooks provide a user-friendly, Jupyter-like interface. To optimize model performance, Kubeflow Katib offers advanced hyperparameter tuning capabilities.
The Kubeflow Model Registry acts as a centralized repository, supporting model versioning and lifecycle management. For deploying and operationalizing ML models, Kubeflow Serving facilitates both real-time and batch inference, ensuring versatile deployment options. Together, these components empower data scientists and engineers to build, manage, and scale ML solutions efficiently within Kubernetes environments.
Key Strengths of Kubeflow
Scalability and Flexibility
Built on Kubernetes, Kubeflow efficiently handles large-scale machine learning (ML) workloads. It dynamically allocates resources, making it ideal for both small experiments and enterprise-level ML systems.
Community and Ecosystem Support
Supported by a vibrant community, Kubeflow benefits from active contributions and frequent updates. This ensures robust features, extensive documentation, and solutions to emerging challenges.
Comprehensive Toolset
Kubeflow provides an integrated suite of tools for every stage of the ML lifecycle, including data preprocessing, training pipelines, hyperparameter tuning, and model deployment.
Weaknesses of Kubeflow
Complexity
Setting up and managing Kubeflow can be highly intricate, particularly for users who lack prior experience with Kubernetes. Its multi-component architecture and dependencies add to the complexity.
Steep Learning Curve
A robust understanding of Kubernetes and container orchestration is essential. For beginners, mastering these concepts before effectively using Kubeflow can require significant time and effort.
MLflow: An Open-Source Platform for the ML Lifecycle
MLflow is a comprehensive platform designed to streamline the machine learning lifecycle, making it easier to track, manage, and deploy ML models. It includes four core components that cater to different stages of ML workflows. MLflow Tracking enables logging parameters, metrics, and artifacts from ML experiments, ensuring reproducibility and facilitating in-depth analysis, much like a roofing inspection checklist helps systematically document and evaluate every critical aspect of a roof’s condition.
MLflow Projects standardize the packaging of ML code into reproducible formats, promoting collaboration and efficient sharing among teams. MLflow Models offers tools to manage and deploy models in multiple formats like Python functions and Spark UDFs. Finally, the MLflow Registry provides a centralized repository for storing, managing, and versioning models, complete with metadata for better oversight.
Key Strengths of MLflow
Simplicity and Ease of Use
MLflow is user-friendly, with straightforward setup and operation, catering to both beginners and advanced users.
Flexibility
It supports a wide array of machine learning frameworks and deployment environments, ensuring adaptability for diverse workflows.
Strong Ecosystem
MLflow boasts a thriving community with ongoing developments, integrations, and plugins that enhance functionality and interoperability.
Weaknesses of MLflow
Limited Scalability
While MLflow can scale to some extent, it may not be as scalable as Kubeflow for large-scale ML workloads.
Less Comprehensive Toolset
Compared to Kubeflow, MLflow offers a more focused set of tools, which may require additional integration with other tools for a complete MLOps solution.
Kubeflow vs. MLflow: A Comparative Table
| Feature | Kubeflow | MLflow |
|---|---|---|
| Platform Type | Kubernetes-native | Standalone |
| Scalability | Highly scalable | Less scalable |
| Ease of Use | Steeper learning curve | User-friendly |
| Flexibility | Highly flexible | Flexible |
| Community Support | Strong community | Smaller community |
| MLOps Lifecycle Coverage | Comprehensive | Comprehensive |
Choosing the Right Platform for Your MLOps Needs
Selecting between Kubeflow and MLflow depends on the unique demands of your machine learning projects and the expertise of your team. If your team excels in Kubernetes and container orchestration, Kubeflow offers powerful tools for managing large-scale, complex workflows. On the other hand, MLflow’s simplicity makes it a user-friendly choice for teams focused on streamlined experimentation and deployment processes.
For projects requiring high scalability or intricate workflows, Kubeflow provides robust scalability, model training, and deployment capabilities. Conversely, smaller projects might benefit more from MLflow’s ease of use and flexibility. Integration with your existing infrastructure is crucial—evaluate how well each platform fits with your cloud services, on-premises clusters, or other tools.
Additionally, consider factors like cost, community support, and long-term maintenance needs, as these can influence productivity and the overall success of your machine learning operations.
Conclusion
Both Kubeflow and MLflow are powerful tools that can significantly enhance your MLOps workflow. The choice between the two depends on your specific needs, team expertise, and project scale. Kubeflow, with its Kubernetes-native approach, offers exceptional scalability and flexibility for complex, large-scale ML projects. MLflow, on the other hand, provides a user-friendly and flexible platform for a wide range of ML tasks. By carefully considering these factors, you can select the most suitable platform to streamline your MLOps journey and drive innovation in your organization.