
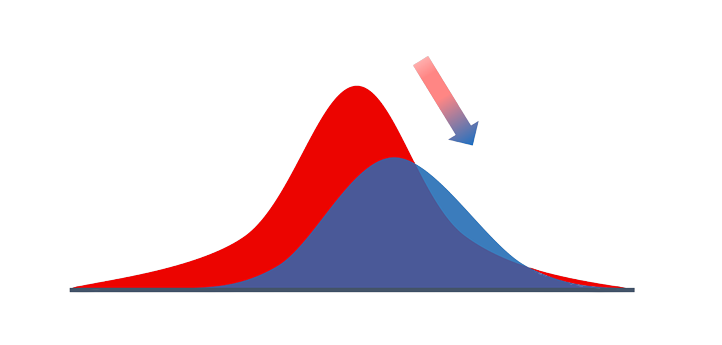
- Visualization Techniques
Histograms effectively illustrate the distribution of individual features, while box plots allow for a comparative analysis of feature distributions across various periods. Scatter plots help in identifying shifts in relationships between different features over time.
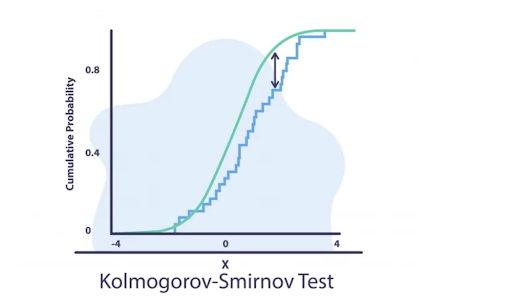
Statistical Tests
Statistical tests are crucial for data drift detection, with each serving distinct purposes. The Kolmogorov-Smirnov test assesses the differences between the cumulative distribution functions of two samples, while the Chi-squared test evaluates the independence of categorical variables. Additionally, the t-test compares the means of two samples to determine if they significantly differ from one another.
Machine Learning-based Methods
Machine learning techniques play a vital role in data drift detection, particularly through methods such as anomaly detection, which identifies data points that significantly diverge from established patterns, and change point detection, which recognizes moments in time when the data distribution shifts abruptly.
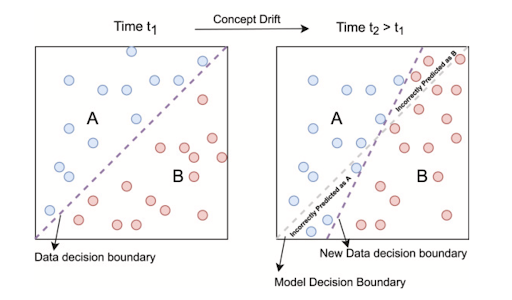
Concept drift refers to a situation where the fundamental relationship between input features and the target variable shifts over time, rendering the decision boundary established during the model’s training outdated. This evolution in the relationship signifies that the model may no longer perform accurately in predicting outcomes.
Concept drift is characterized by significant shifts in the decision boundary, indicating altered correlations between input features and the target variable. It often arises from external influences like changing economic conditions, technological advancements, or evolving consumer behaviors, and can be more difficult to detect than data drift due to its subtle nature.
- Continuous Learning
Implement mechanisms for the model to learn from new data and adapt to changing concepts.
- Active Learning
Prioritize data collection for areas where the model is uncertain or performing poorly.
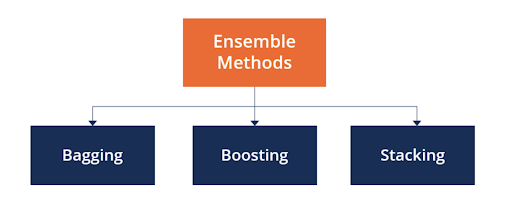
- Ensemble Methods
Combine multiple models to improve robustness and reduce the impact of concept drift.
- Regular Model Retraining
Periodically retrain the model with updated data to capture new patterns.